
Data classification is an important business process. It makes it easier to apply data protection, helps employees understand what data is sensitive, and, importantly, which data can be made public. Unfortunately, many organizations provide employees with access to far more data than is needed. The oversharing of information with employees is a huge security risk.
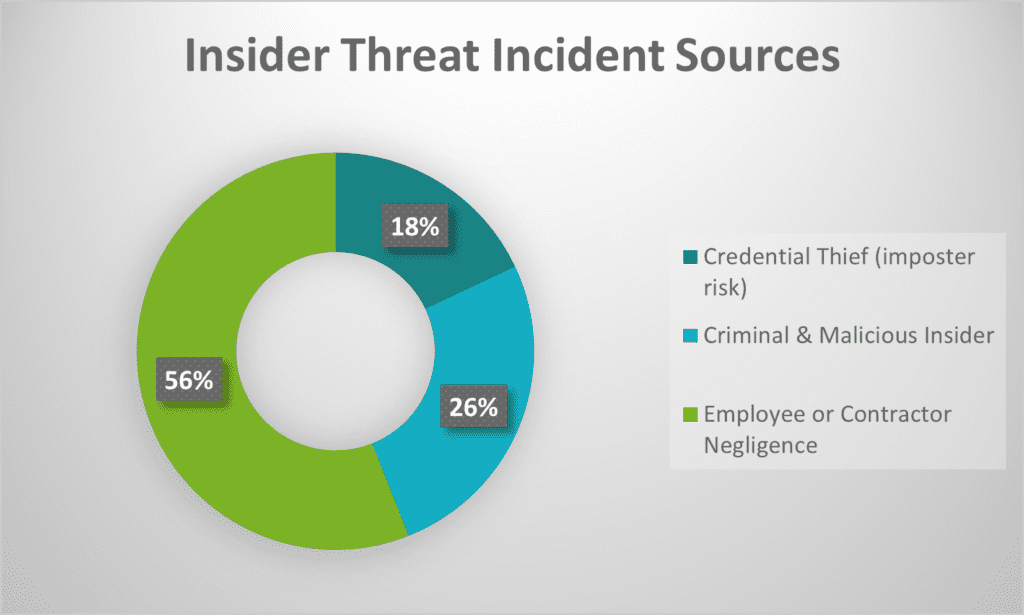
Employee negligence has become a top source of data breaches in recent years. According to the 2022 Cost of Insider Threats Global Report 56% of insider incidents are caused by employee or contractor negligence. While these incidents are not malicious in their intent, they can cause the same amount of damage as one perpetrated by a malicious insider that uses their access for harmful, unethical or illegal activities. These malicious insiders accounted for 26% of all incidents in the report. Worse, simple mistakes and malicious employees or contractors are much harder to detect than breaches caused by hackers and other external bad actors.
In an age of digital transformation, the best practice must be to restrict data access to only those who need that specific data to do their job properly – and nothing more. This principle often referred to as “the principle of least privilege,” greatly reduces an organization’s overall risk of exposure. Data classification is an important step in making this possible.
Protecting the Crown Jewel – Data
A bank is a good analogy to explain the importance of proper classification and data access restrictions. Money and valuables are generally stored inside a vault that a very limited amount of people have access to. Money is one of the most important resources for any bank, so multiple safeguards are in place to restrict access. The same can be said about an organization’s most important asset – data. Why would you give unnecessary access to your most precious resource? Sensitive information, the ‘crown jewel’ of any organization, must be treated with the same care and security protocols as money in the vault.
Data Classification Benefits
Every company has information of varying levels of value and importance. A data classification policy is essential to define the sensitivity levels, impact levels, and data security controls required. Aside from aiding in data protection processes, there are many additional benefits of data classification including:
- Compliance. Many regulatory frameworks focus on a specific type of sensitive data that needs to be protected. For example, GDPR is all about the handling and protection of personal data. Knowing what regulations apply to your organization makes it easier to restrict access to regulated data and employ other data protection tactics.
- Data organization. One of the common challenges to protecting data is knowing where it resides. Surprisingly, many companies don’t where their sensitive data is or how much of it they have. To assist, data classification policies can be fed into a tool that can look for and classify data in your environment accordingly. This will not only help to organize your digital assets but the classifications can also be used to add data protection controls to restrict access and close off potential data leaks.
- Awareness. A published corporate data classification policy ensures employees are aware of how to properly handle potentially sensitive data, minimizing the risk of accidental exposure.
- Cost savings. Many data and access control systems demand a lot of time and money to be implemented properly (IAM, DLP, etc.). Determining the systems that contain your sensitive data helps to focus data protection efforts, saving both time and money. Plus, data breaches are costly. The total cost of a data breach is USD $4.35 million according to the 2022 Cost of a Data Breach Report. Any measures that can be taken to prevent them can provide a quick ROI.
Where to Start? Determining Your Data Classification Levels
Defining your classification levels will depend on the sensitivity of the data that your organization holds. This process should not only define the sensitivity levels; it should also define who should have access to that type of data and how long it needs to be retained.
There are four common classification levels:
- Public data: Data that is freely accessible to the public (i.e., all employees/company personnel). It can be freely used, reused, and redistributed without repercussions or risk. For example, press releases and other public-facing company announcements.
- Internal-only data: Data that needs to be restricted to internal company personnel, groups of personnel or individual employees who are granted access. For example, internal-only communications, business plans, departmental memos, etc.
- Confidential data: Data that requires specific authorization and/or clearance to access it due to its confidential nature. For example, M&A documents or data regulated by privacy laws such as GDPR and HIPAA.
- Restricted data: Highly sensitive data that, if compromised or accessed without authorization, may lead to legal fines, criminal action or damage to the company’s bottom line or competitive advantage. For example, intellectual property (IP) and data protected by government or industry regulations.
Depending on the nature of the data your organization handles there may be additional custom classification levels required. However, it’s best not to create too many categories either. Efficiency can be achieved using only 3-4 different data classification levels. Having too many levels is a sure way to create unnecessary confusion, resulting in misclassification and other problems.
4 Steps to building a data classification policy
While each organization’s approach to classification will differ, there are 4 basic steps for creating a data classification policy:
- Connect with all of your management departments – The best people to ask about the types of data your organization is working with are your business leaders and management. It’s possible that they already have undocumented data policies in place to determine who has access to what kinds of information.
- Identify your most significant risks, from both a legal and regulatory standpoint – There are specific information types that are considered highly sensitive by regulators and require specialized controls. For example, the EU’s GDPR legislation considers sensitive personal data as anything with genetic data, biometric data, ethnic or racial status data, health condition data, and more. Breaches of compliance requirements often result in hefty fines. You’ll need to implement various protection techniques to protect this data such as encryption, access controls, and other file-level protection as mandated by each regulation.
- Define your policies and data classification levels based on your business risks – In this step, you will define the unique data classification levels based on all of the data that you’ve collected in previous steps (sensitive data types, possible risks that exposure might cause, applicable regulations, etc.). There are some specific questions you can ask to assist with this exercise:
“How important is this data for our everyday work?”
“What is the extent of the impact any exposure of this data might cause?”
“What is the retention period for this data according to the regulatory standard(s)?” - Publish and implement the data classification policy – There are several different ways to implement the data classification policy in your organization. For example, employee training and adding the policies into your access and data protection tools to automate enforcement. You’ll need to monitor the effectiveness of your policy after it’s been implemented to measure the positive (or negative) impact and areas that may need improvement.
Data access and protection strategies to use alongside classification
There are many technologies that can help you classify data and leverage the resulting classifications to automate and improve data security to mitigate risks. Look to augment your data classification program with technologies that can help:
- Discover unclassified sensitive data.
- Dynamically classify data based on the sensitivity of its contents and your classification policies.
- Limit what privileged administrative accounts can do with data. For example, prevent admins from being able to open and read sensitive information.
- Enforce strong access controls to grant or deny access to a specific piece of sensitive data.
- Prevent sharing of sensitive data with unauthorized parties.
- Implement encryption tools to protect your data at rest and in transit.
- Restrict how sensitive data is presented to users. For example, limiting a sensitive file to read-only access.
- Watermark sensitive data to alert users to its sensitivity.
- Redact sensitive data. For example, redacting an address or phone number from a resume that is being circulated to interviewers.
Automating the Classification Process
Data classification is an important step toward protecting the data in your care and reducing the risk of unintentional exposure, data leaks and breaches. While there are many different approaches to a successful data classification program, none of these steps are effective without knowing where your data is located and what it contains.
Discover how NC Protect automates the discovery, classification and protection of sensitive data to help put your classification program into action. NC Protect finds your organization’s sensitive data, classifies and secures it with dynamic conditional security across your Microsoft collaboration tools in on-premises, cloud or hybrid environments. It can even use existing classifications from other tools or Microsoft Purview Information Protection (MPIP) labels to apply dynamic information protection using those classifications. It tracks access to files and what actions have been taken with them, providing a full audit trail for compliance and reporting.
Learn more about NC Protect’s classification and unique data protection capabilities.
How to Manage Information Security & Governance in M365 & SharePoint
This step-by-step guide lays out each phase; from defining your governance strategy to implementing a solution to automate classification, access and protection policies.
